Hilltop优化算法是由Krishna Baharat 在2000年上下科学研究的,于二零零一年专利申请,可是有很多人认为Hilltop优化算法是由Google科学研究的。只不过Krishna Baharat 之后添加了Google变成了一名关键技术工程师,随后受权给Google应用的。
在与PageRank优化算法比较之下,Google意识到这一优化算法的发展会为她们的自然排名产生十分关键的作用。Google的HillTop优化算法如今早已能更强的与旧的优化算法(PR优化算法)协同起來工作中。依据观查HillTop优化算法相比它在2000年刚设计方案的情况下早已拥有非常大的发展。显而易见这也是二零零三年11月16日“佛罗里达州”升级中危害的一个最关键的优化算法。
1. Hilltop优化算法基础观念
Hilltop结合了HITS和PageRank2个优化算法的基础观念:
一方面,Hilltop是与客户查看要求有关的链接分析优化算法,消化吸收了HITS优化算法依据客户查看得到 高品质有关网页页面非空子集的观念,即主题风格有关网页页面中间的连接针对权重系数的奉献比主题风格不有关的连接使用价值要高些.合乎“非空子集传播模型”,是该实体模型的一个实际案例;
另一方面,在权重值散播全过程中,Hilltop也听取意见了PageRank的基础指导方针,即根据网页页面入链的总数和品质来明确百度搜索的排列权重值。
2. Hilltop优化算法的一些基础界定
非依附机构网页页面:
“非依附机构网页页面”(Non-affiliated Pages)是Hilltop优化算法的一个很重要的界定。要掌握什么是非依附机构网页页面,需先搞搞清楚什么叫“依附机构网址”,说白了“依附机构网址”,即不一样的网址归属于同一组织或是其拥有人有紧密关系。实际来讲,考虑以下随意一条分辨标准的网址会被觉得是依附网址:
标准1:服务器IP地址的前三个子子网同样,例如:IP地址各自为159.226.138.127和159.226.138.234的2个网址会被觉得是依附网址。
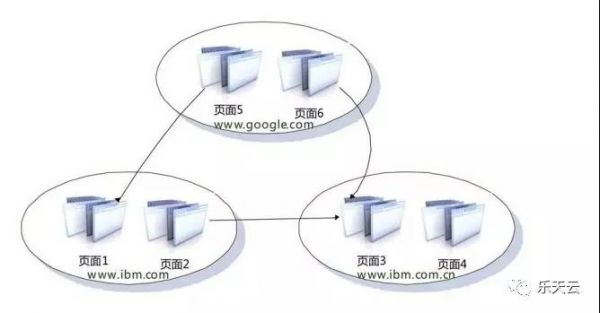
标准2:假如域名中的主网站域名同样,例如:www.ibm.com和www.ibm.com.cn会被觉得是依附机构网址。
“非依附机构网页页面”的含意是:假如2个网页页面不属于依附网址,则为非依附机构网页页面。图6-22是有关平面图,从图上能够看得出,网页页面2和网页页面3同归属于IBM的网页页面,因此 是“依附机构网页页面”,而网页页面1和网页页面5、网页页面3和网页页面6全是“非依附机构网页页面”。从而也可看得出,“非依附机构网页页面”意味着的是网页页面的一种关联,单独一个网页页面是不在乎依附或是非依附机构网页页面的。