昨日在《js 正则学习小记之匹配字符串字面量》提到 /"(?:\\.|[^"])*"/ 是个非常好的关系式,由于能够考虑大家的规定,因此 这一关系式能用,但不一定是最好是的
昨日在《js 正则学习小记之匹配字符串字面量》提到 /"(?:\\.|[^"])*"/ 是个非常好的关系式,由于能够考虑大家的规定,因此 这一关系式能用,但不一定是最好是的。
从特性上而言,他十分槽糕,为何那么说呢,由于 传统NFA模块 碰到支系是从左到右搭配的,
因此 它会用 \\. 去搭配每一个字符,发觉不对后才用 [^"] 去搭配。
例如那样一个字符串数组: "123456\'78\"90"
共 16 字符,除开第一个 " 立即搭配取得成功,还剩下 15 个,仅有 2 个转义(4 字符),因此 \\. 会不成功 10 次,仅有 2 次取得成功。
这 10 次搭配不成功,必须回朔后用 [^"] 才可以搭配取得成功,自然最后一个 " 会立即搭配取得成功。
很显著,一切正常的字符串数组不太可能都是转义,一切正常的字符串数组才算是流行,自然不清除有些人有意全转义的状况。
因此 这一正则表达式必须10次回朔后才可以搭配进行,假如字符串数组提高到 1K 1M 咋整破呢?
因此 我们要改动下这一正则表达式,前后左右换下来部位么?
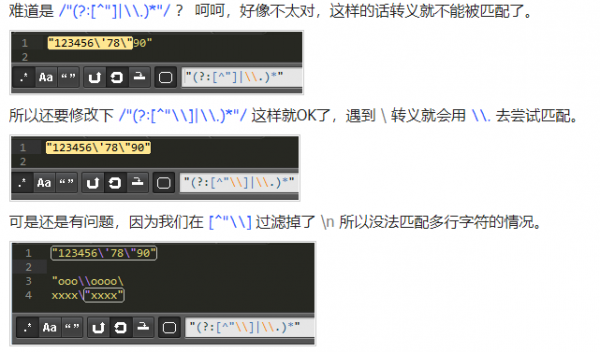
js 中 字符串数组用 \ 折行是容许的,可是改动后的 正则表达式 无法搭配那样的字符串数组了,因此 大家还得再次恢复。
由于 . 无法搭配自动换行,因此 我们要用别的方法表述。
. 是用以搭配除换行符以外的全部标识符,难道说我们要 [.\n] 来表明么?
那样不是对的,由于 [] 字段名中的 . 已不表明除换行符以外的全部标识符,只是标识符 . 也就是他自身一个字符罢了。
那怎么办呢?
实际上换一个构思,
\d 表明 0-9
\D 表明 [^0-9]
那麼 [\d\D] 就表明全部了,并不是么。(新手盆友不清楚是否可以使消化吸收这一知识要点。)
同样 [\s\S] [\w\W] 一样能够。
因此 /"(?:[^"\\]|\\[\d\D])*"/ 那样就考虑大家的规定了。
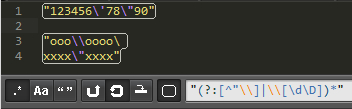
实际效果非常好。
回首回来分剖析下他如今的特性吧。
還是这一字符串数组: "123456\'78\"90" , 正则表达式 /"(?:[^"\\]|\\[\d\D])*"/
共 16 字符,除开第一个 " 立即搭配取得成功,还剩下 15 个,有 2 个转义(4 字符),[^"\\] 能搭配取得成功 10 字符,仅有 2 次不成功。
为何并不是 4 次不成功呢,本来有4个标识符啊。\\ 尽管是两个标识符,可是读到第一个 \ 就搭配不成功,随后用 \\[\d\D] 搭配取得成功,
